Full and Incremental Duplicate Search Algorithm
To identify duplicates, the full and incremental search processes leverage the soundex phonetic algorithm and Damerau-Levenshtein distance algorithm to calculate the similarity between constituent records.
This is a summary of the matching process:
-
The program prepares the results table. For a full duplicate search, all data is cleared from previous searches. For an incremental search, the program only clears constituents that no longer exist in the database. If Include inactive is not selected for the search process, the program also clears inactive constituents.
-
The program creates groups of constituents to compare by running the soundex algorithm on the constituent key names (Last name for individuals or the Org/Group/Household name for organizations/groups/households). This algorithm finds names that sound the same but have minor differences in spelling. For example, the last names Hendericks, Hendershot, Henderson, and Hunter all have the soundex value of H536. They are included in the same group for comparison, while constituents with last names like Anderson, Johnson, Cooke, or Higgins are included in other groups. For a detailed explanation of the soundex algorithm, see http://en.wikipedia.org/wiki/soundex. The program divides these groups by constituent type (Individuals, Groups, and Organizations) and then compares each group separately.
Note: Because the soundex algorithm matches records based on phonetic similarity, you should use articles at the beginning of organization names consistently-either always or never include them. For example, "The Boys and Girls Club" and "Boys and Girls Club" are not identified as duplicates by the full or incremental duplicate search processes due to the phonetic differences of the first word.
-
The program then uses four calculations to compare the key name of each constituent to every other constituent in that group. For more information about those calculations, see Matching Score Calculations.
If the key names on two constituents are similar enough to meet or exceed the match confidence threshold for names, the program then runs calculations for email addresses, phone numbers, and addresses:
-
If Match constituents based on email address is selected for the search process, the program also compares email addresses. If they match exactly, the program uses this calculation for the matching score: (1 + Name Score) / 2. For example, if the Name Score is .8, the result is (1 + .8) / 2 = .9 (90% match). If they do not match exactly, the score is zero.
-
If Match constituents based on phone number is selected for the search process, the program also compares phone numbers. If they match exactly, the program uses this calculation for the matching score: (1 + Name Score) / 2. For example, if the Name Score is .95, the result is (1 + .95) / 2 = .975 (98% match). If they do not match exactly, the score is zero.
-
If neither the email nor phone number is an exact match, the program compares addresses. If the addresses are similar enough to meet or exceed the match confidence threshold for addresses, the program uses this calculation for the matching score: (Name Score + Address Score) / 2.
-
Constituents identified as duplicates are added to the table, while invalid matches are filtered from the results. Invalid matches include: constituents with a relationship to one another, constituents in the same Group/Household, and constituents that only matched themselves and no other constituents. If a constituent qualifies as a duplicate for multiple constituents, it is only matched to the constituent with the highest score.
-
After scoring each match, the program creates matching groups that determine which constituents are merged and in what order. This can get complicated when you have four or more potential matches and not one of them matches every other record in the group. For example, a group includes: Mark P. Gardner (A), Mark Gardner (B), M P. Gardner (C), and M Gardner (D).
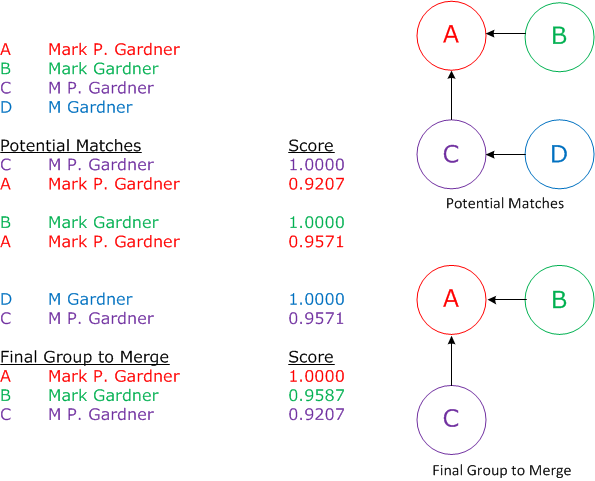
The program designates Mark P. Gardner as the anchor record and compares it to every other record in the match group. Based on the matching scores, M P. Gardner and Mark Gardner match Mark P. Gardner. And M Gardner matches M P Gardner. Because M Gardner does not match the anchor record (Mark P. Gardner), the program excludes M Gardner and will not merge it with the others.
 Matching Score Calculations
Matching Score Calculations
To calculate match confidence scores, the program uses the Damerau-Levenshtein distance algorithm to make four comparisons.
-
The first calculation uses the Damerau-Levenshtein distance algorithm to compare strings (full name, address, email, and phone) and identify the number of changes necessary to make the strings match exactly. Changes include adding, removing, or changing characters and transposing a pair of characters. For example, if you compare "Christopher" vs. "Chrsitopher," you would need to transpose the "si" in "Chrsitopher" to fix the misspelling (one change). To learn more about this algorithm, see http://en.wikipedia.org/wiki/Damerau-Levenshtein_distance.
-
The second calculation breaks each string (email, phone, and address) into individual words and applies the Damerau-Levenshtein distance algorithm to each word pair on the matching constituents. It then averages the scores calculated for all words pairs. If a string on one constituent contains all the words of the string of a matching constituent, the words are considered exact matches. For example, "32 Broad St" and "32 Broad" are matches.
-
The third calculation breaks each string (full name, address, email, and phone) into words and each word into groups of four characters (q-grams) and then applies the Damerau-Levenshtein distance algorithm to each q-gram on the matching constituents. It then averages the scores calculated for all q-grams. To learn more about q-grams, see http://www.sound-ex.com/alternative_qgram.htm.
-
The final calculation breaks the string (full name, address, email, and phone) into q-grams without first breaking it into words and then applies the Damerau-Levenshtein distance algorithm to each q-gram on the matching constituents.
The final match confidence score equals the highest score of those four calculations. Some important notes to consider:
-
The program runs each calculation in the order listed above. If the first or second calculation produce a matching score of 100%, the constituents are considered perfect matches and the program runs no further calculations, with one exception - in the second calculation, if a string on one constituent contains all the words of a string on a matching constituent, the matching score is 100%. Because this situation may occur for records that are not true perfect matches, the program registers the score as 95% instead and runs no further calculations. This may impact the accuracy of matching scores because the matching score remains 95% even if the third or fourth calculations would have produced scores higher than 95%. This also means that strings such as "John and Jane Doe" and "Jane Doe" will have a score of 95% even though you probably would not want to merge those constituents.
-
As another measure to prevent false perfect matches (a true perfect match would be identified in the first or second calculation), the third calculation cannot produce a score of 100%. If the mathematical result equals 100%, the program registers the score as 98%.
-
The algorithm compares names as a whole, including middle names and maiden names if Include middle names in comparison and Include maiden names in comparison are selected for the search. (These options are selected for fast and detailed searches by default.)
For constituents with the same last name, if one constituent has the same first name as the other's middle name, high match scores can occur, which may flag those constituents as potential duplicates. This is because each part of a name, separated by spaces, is compared with each part of the other's name. For example, John Michael Doe and Michael Doe score high as matches because the 'Michael' part of the first constituent's name is compared to the 'Michael' and 'Doe' part of the other's name. More generally, when part of a constituent's name matches part of another constituent's name, the score increases. If the middle name or maiden name is missing, the match % is reduced accordingly.