Duplicate Detection Process
To help with data hygiene and positive constituent relationships, Raiser's Edge NXT automatically detects possible duplicate records in your database. After an initial run of your entire database, the detection runs continuously to process new and updated records. Each potential duplicate set is identified, along with a confidence score for each match.
The detection compares email addresses first because they provide the greatest degree of confidence for potential matches. When searching for potential duplicates by name, the last names must match exactly, as well as the first three characters of the first name. The detection does not match potential duplicates by "sounds like" names.
The algorithm compares these fields and assigns a score:
-
First name, middle name, last name
-
Gender
-
Suffix
-
Address number and address street
-
Postal code
Note: Raiser's Edge NXT also uses machine learning to track which records customers mark as duplicates throughout the web view to further refine this algorithm.
Based on this comparison, the detection initially gathers a set of potential duplicates. An algorithm then compares each set of duplicates and assigns a score based on the confidence of the match. Only sets with a confidence score above a certain threshold are kept, and the other sets are discarded from the process.
The diagram below demonstrates how duplicates are found for a set of constituents:
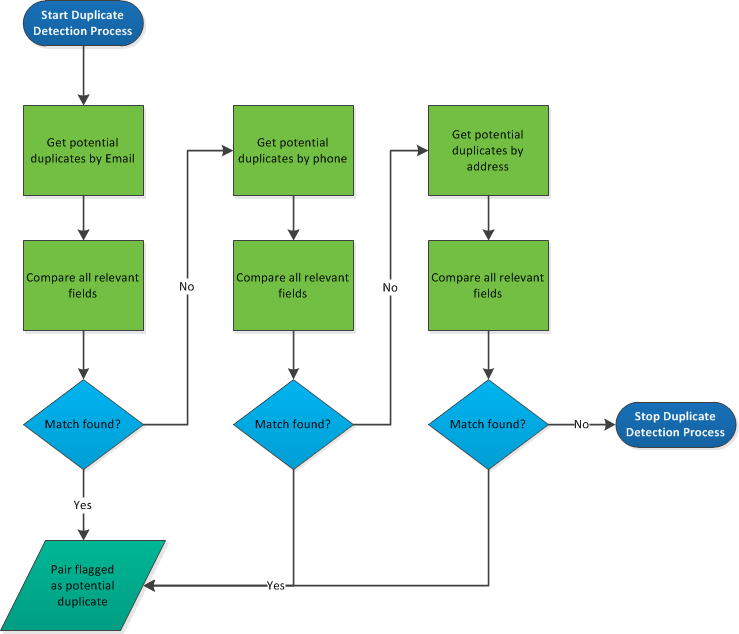
Note: In a few cases, records don't appear as potential duplicates, even if the duplicate detection criteria apply. This happens when two records are connected through a relationship or when two records have different graduating class years.